Paper abstract
A cleaner interface for the executor.
Generalization remains a central bottleneck for vision-language-action (VLA) models: under
distractors, appearance shifts, and semantically similar tasks, the policy must often infer local
execution details from coarse instructions while also deciding which parts of the image matter
for control. We present S2 (See Less, Specify More), a framework for improving VLA
generalization by training the executor under a cleaner interface. Specify More preserves the
original instruction as a stable high-level goal while relabeling each trajectory into refined
trajectory- and subtask-level language that disambiguates the current execution mode. Unlike
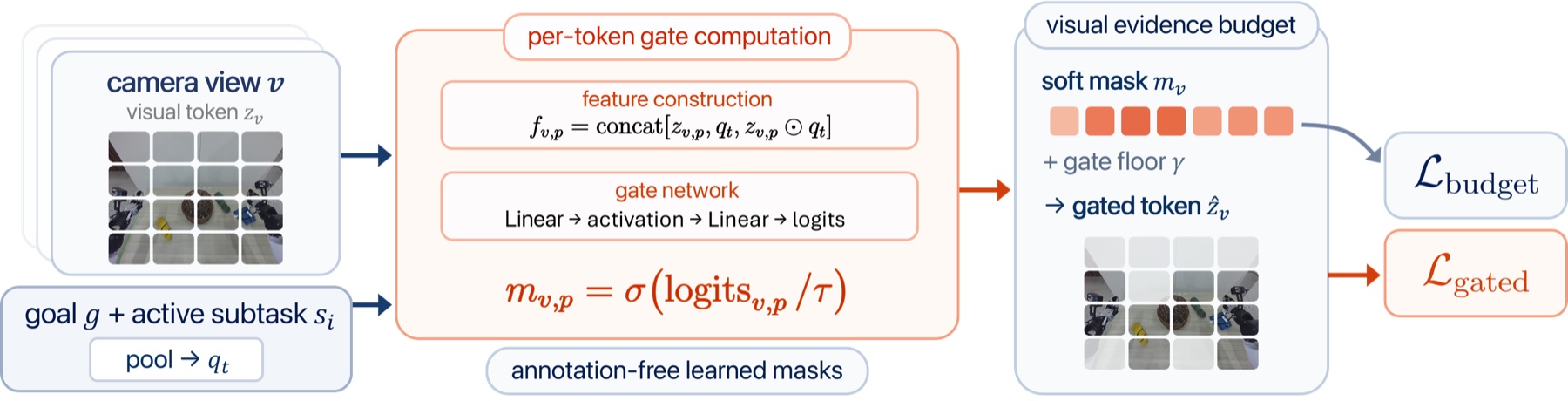
native attention, See Less imposes an explicit visual evidence budget, training the executor to
act from task-sufficient evidence rather than unconstrained visual context, without any region
or mask annotation. This interface lets the executor follow detailed guidance without relying on
distracting visual patches or resolving avoidable ambiguity on its own, and it remains
compatible with off-the-shelf VLM planners through in-context learning. Across our main
evaluation settings, S2 improves overall generalization metrics by changing the executor's
learning problem: coarse instructions induce avoidable supervision aliasing, goal-preserving
local guidance outperforms instruction replacement in our main ablations, and explicit evidence
budgeting reduces dependence on broad visual context beyond efficiency considerations. Across
eight real-robot tasks on TX-G2 (an AgiBot G2-compatible variant) and HSR, S2 raises mean
subtask success from 54.2% to 79.0% over π0.5. Together, these results suggest that
VLA generalization improves when the executor is trained to act from informative local guidance
and task-sufficient visual evidence, rather than recovering both from weak supervision.